用Apache Tika解析文档
作者:程序员马丁
热门项目实战社群,收获国内众多知名公司面试青睐,近千名同学面试成功!助力你在校招或社招上拿个offer。
读文件没那么简单
假设你正在做一个毕业设计:构建一个基于大模型的智能问答系统,用户可以上传公司内部文档,然后针对这些文档进行提问。
听起来很清晰,技术路线大概是:
用户上传文档 → 解析文档内容 → 存入向量数据库 → 用户提问 → 检索相关内容 → 喂给大模型 → 返回答案
你可能觉得"解析文档内容"这一步很简单——不就是读文件吗?
// 你以为的代码
String content = Files.readString(Path.of("report.pdf"));
然后你会发现:这行代码根本跑不通。
1. 你以为的文档解析 vs 真实世界的文档
1.1 PDF:同一个后缀,完全不同的内心
你收到三份 PDF 文件:
| 文件 | 来源 | 你尝试复制粘贴 | 结果 |
|---|---|---|---|
report1.pdf | Word 导出的 | 能复制 | 正常 |
report2.pdf | 扫描仪扫的 | 选不中任何文字 | 空白 |
report3.pdf | 某老系统生成 | 复制出来全是乱码 | ¿½Ð |
同样是 .pdf 后缀,内部结构可能完全不同:
- 文字型 PDF:内部存储的是文字编码,可以直接提取。
- 扫描型 PDF:内部存储的是图片,文字只是“画”上去的。
- 混合型 PDF:部分页是文字,部分页是扫描图。
你写的 readString() 根本不知道怎么处理这些差异。
1.2 Word 文档:远比你想象的复杂
一份 .docx 文件,打开看起来就是几段文字。但你用代码读出来可能是这样:
公司简介
成立时间 2015年
员工人数 500人
第 1 页,共 3 页
本文档为内部资料,请勿外传
问题在哪?
- 表格被拆成了莫名其妙的换行。
- 页眉页脚混进了正文。
- 多余的空行和空格。
- 文档属性(作者、创建时间)你根本没拿到。
1.3 文件后缀:会骗人的
File file = new File("data.txt");
// 你以为是文本文件,其实...
真实场景:
- 有人把
.xlsx改成了.txt(怕被邮件系统拦截)。 - 有人把
.exe改成了.docx(别问为什么)。 - 有人上传的
.pdf其实是 HTML 改的后缀。
只看后缀判断文件类型 = 100% 会翻车。
1.4 编码问题:中文乱码重灾区
鎮ㄥソ锛屾杩庝娇鐢? // 这是什么鬼?
原因:文件是 GBK 编码,你用 UTF-8 读取。
或者反过来:文件是 UTF-8,你用 GBK 读取。
更惨的情况:一份文档里混合了多种编码(别笑,真的有)。
2. 当你要构建 RAG 知识库时,这些问题会全部爆发
2.1 为什么文档解析是第一道坎?
RAG 的核心思路是:
不要让大模型凭空回答,而是先从你的文档库里检索相关内容,把检索结果喂给大模型,让它基于这些内容来回答。
2.2 如果文档解析这一步出了问题
| 问题 | 后果 |
|---|---|
| 扫描 PDF 解析为空 | 这份文档的知识完全丢失 |
| 表格变成乱换行 | 检索时匹配不到,或者匹配到无意义片段 |
| 元数据丢失 | 用户问“这是哪个部门的文件”,你答不上来 |
| 乱码 | 向量化结果是垃圾,检索结果也是垃圾 |
| 页眉页脚混入 | 每个切片都带着“第X页/共Y页”,浪费 token |
结论:文档解析的质量,直接决定了你整个 RAG 系统的上限。
3. 专业的文档解析工具
到这里,你应该理解了:解析文档不是一个 readFile() 能搞定的事。
你需要一个工具:
- 能自动识别文件的真实类型(不靠后缀)
- 能处理几十种文档格式(PDF、Word、PPT、Excel、HTML、邮件...)
- 能提取文本内容。
- 能提取元数据(作者、创建时间、标题...)
- 能处理编码问题。
- 能对接 OCR(处理扫描件)
- 最好是开源免费的。
这个工具就是 Apache Tika。
GitHub 地址:https://github.com/apache/tika
认识 Apache Tika
1. Tika 解决什么问题
Apache Tika 是 Apache 基金会的开源项目,专门用于内容检测和内容提取。
用一句话概括:
给 Tika 一个文件(不管什么格式),它还你干净的文本和元数据。
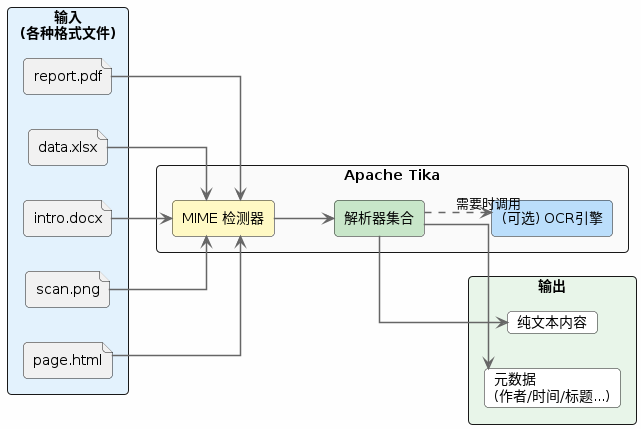
2. Tika 支持的文件格式
Tika 支持 1000+ 种 MIME 类型,常见的包括:
| 类别 | 格式 |
|---|---|
| 文档 | PDF, DOC, DOCX, ODT, RTF, TXT |
| 表格 | XLS, XLSX, CSV, ODS |
| 演示 | PPT, PPTX, ODP |
| 图片 | JPG, PNG, GIF, TIFF, BMP |
| 网页 | HTML, XML, XHTML |
| 压缩 | ZIP, TAR, GZIP, 7Z |
| 邮件 | EML, MSG, MBOX |
| 电子书 | EPUB, MOBI |
| 音视频 | MP3, MP4, AVI(提取元数据) |
3. 两种使用方式
| 方式 | 说明 | 适用场景 |
|---|---|---|
| 作为 Java 依赖库 | 直接在项目中引入 tika-core 和 tika-parsers,代码里调用 | 单体应��用、解析量不大、对延迟敏感 |
| 作为独立服务(Tika Server) | 用 Docker 跑一个 Tika 服务,通过 HTTP 接口调用 | 微服务架构、多语言、需要隔离、解析量大 |
咱们下文主要以 Java 依赖库 的方式来讲解;至于 独立服务部署 这种形态,大家了解即可。当然,我也会顺带说明两者的区别,以及各自更适合的使用场景。
核心概念详解
1. MIME 类型:文件的身份证
1.1 什么是 MIME 类型
MIME(Multipurpose Internet Mail Extensions)类型是互联网标准,用于标识文件的真实格式。
格式是 类型/子类型,比如:
| MIME 类型 | 对应格式 |
|---|---|
text/plain | 纯文本 |
text/html | HTML |
application/pdf | |
application/vnd.openxmlformats-officedocument.wordprocessingml.document | DOCX |
image/png | PNG 图片 |
application/zip | ZIP 压缩包 |
1.2 为什么不能只看文件后缀
// 危险的做法
if (filename.endsWith(".pdf")) {
// 当作 PDF 处理
}
问题 1:后缀可以随便改
mv malware.exe report.pdf # 后缀是 pdf,内容是 exe
问题 2:后缀可能丢失
# 有些系统传文件会丢后缀
upload_12345678 # 这是什么文件?
问题 3:后缀和内容不匹配
用户把 Excel 文件后缀改成 .txt 发邮件(绕过附件限制),你的系统收到后按 .txt 处理,直接炸了。
1.3 Tika 如何检测真实 MIME 类型
Tika 使用魔数检测(Magic Number Detection):
PDF 文件的前几个字节是:%PDF-
ZIP 文件的前几个字节是:PK
PNG 图片的前几个字节是:‰PNG
Tika 读取文件的头部字节,与已知的签名库比对,从而判断真实类型。
// Tika 检测 MIME 类型
Tika tika = new Tika();
String mimeType = tika.detect(new File("unknown_file"));
// 返回 application/pdf,不管文件后缀是什么
2. 文本抽取:拿到可用的文字内容
2.1 什么是文本抽取
从各种格式的文件中,提取出纯文本内容。
输入:一份带格式的 Word 文档(有字体、颜色、表格、图片)
输出:纯文字字符串(没有格式信息)
2.2 为什么不能直接读字节
byte[] bytes = Files.readAllBytes(Path.of("report.docx"));
String content = new String(bytes, StandardCharsets.UTF_8);
// 结果:一堆乱码 + 不可见字符
因为 .docx 本质是一个 ZIP 压缩包,里面是一堆 XML 文件。你直接读字节,读到的是 ZIP 的二进制结构。
2.3 文本抽取在 RAG 中的价值
| 用途 | 说明 |
|---|---|
| 向量化 | 只有文本才能被 Embedding 模型处理 |
| 全文检索 | ElasticSearch 等搜索引擎索引的是文本 |
| 切片 | 按句子/段落切分,需要先有文本 |
| 展示 | 给用户看原文片段 |
3. 元数据抽取
3.1 什么是元数据
元数据(Metadata)是“关于数据的数据”,描述文档本身的属性。
常见的元数据:
| 字段 | 说明 | 示例 |
|---|---|---|
Content-Type | MIME 类型 | application/pdf |
title | 文档标题 | 2024年度报告 |
creator | 作者/创建者 | 张三 |
created | 创建时间 | 2024-01-15T10:30:00 |
modified | 修改时间 | 2024-03-20T14:00:00 |
pageCount | 页数 | 15 |
wordCount | 字数 | 5000 |
3.2 元数据在 RAG 中的价值
场景 1:溯源
用户问:这个信息来自哪份文档?
如果你保存了元数据,可以回答:来自《2024年度报告》,作者是张三,创建于2024年1月15日。
场景 2:过滤
用户说:只搜索最近一年的文档。
如果你有 created 字段,可以做时间过滤。
场景 3:权限控制
某些文档有 department: 财务部 的元数据,只有财务部员工能查。
3.3 Tika 提取元数据示例
Metadata metadata = new Metadata();
// ... 解析文件 ...
// 获取元数据
String author = metadata.get("creator");
String title = metadata.get("title");
String createDate = metadata.get("dcterms:created");
4. OCR
4.1 什么是 OCR
OCR(Optical Character Recognition,光学字符识别)是一种技术,能把图片中的文字识别成可编辑的文本。
输入:一张包含文字的图片
输出:图片中文字的字符串
4.2 什么时候需要 OCR
| 场景 | 需要 OCR 吗 |
|---|---|
| Word 导出的 PDF | 不需要,文字可直接提取 |
| 扫描仪扫描的 PDF | 需要,内部是图片 |
| 手机拍的照片 | 需要,是图片 |
| PNG/JPG 图片 | 需要,是图片 |
| 截图 | 需要,是图片 |
4.3 Tika 与 OCR 的关系
Tika 本身不包含 OCR 引擎,但可以对接外部 OCR 工具:
- Tesseract(开源,最常用)
- Adobe Acrobat(商业)
- ABBYY(商业,效果最好)
当 Tika 发现 PDF 里某一页是图片时,会调用配置好的 OCR 引擎。
4.4 OCR 的局限性
| 问题 | 说明 |
|---|---|
| 速度慢 | 比直接文本提取慢 10-100 倍 |
| 准确率有限 | 手写字、模糊图片、特殊字体可能识别错误 |
| 需要额外依赖 | 要安装 Tesseract 等 |
| 资源消耗大 | CPU 和内存占用高 |
建议:先尝试直接文本提取,只有提取为空/内容过少时再走 OCR。
5. 解析失败的常见原因与处理策略
5.1 常见的解析问题
| 问题 | 表现 | 原因 |
|---|---|---|
| 空文本 | 解析结果是空字符串 | 扫描 PDF 没配 OCR;加密文档 |
| 乱码 | 出现 锟斤拷 ¿½ | 编码不匹配 |
| 内容缺失 | 只有部分内容 | 解析器不支持某些特性 |
| 格式混乱 | 大量无意义换行/空格 | 表格、多栏排版 |
| 解析报错 | 抛出异常 | 文件损坏;格式不支持 |
| 超时 | 解析很久不返回 | 文件太大;复杂嵌套 |
把 Tika 当 Java 依赖库
1. 创建项目并添加依赖
1.1 开箱即用 SpringBoot-Ladder
Gitee 地址:https://gitee.com/nageoffer/springboot-ladder
项目介绍:从零到一学习 SpringBoot 各种组件框架实战的项目,让 Demo 变得简单。
1.2 添加 Tika 依赖
在 pom.xml 中添加:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.nageoffer.springboot-ladder</groupId>
<artifactId>springboot-ladder-all</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>springboot-ladder-tika-3x</artifactId>
<properties>
<tika.version>3.2.3</tika.version>
</properties>
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Apache Tika 核心 -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>${tika.version}</version>
</dependency>
<!-- Apache Tika 解析器(包含各种格式支持) -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>${tika.version}</version>
</dependency>
</dependencies>
</project>
1.2.1 关于依赖的说明
| 依赖 | 说明 |
|---|---|
tika-core | Tika 核心功能,包括 MIME 检测 |
tika-parsers-standard-package | 标准解析器集合,支持 PDF/Word/Excel 等常见格式 |
注意:tika-parsers-standard-package 会引入很多传递依赖,因为它要支持各种格式。
2. 编写文档解析服务
2.1 创建解析结果 DTO
/**
* 文档解析结果
*/
@Setter
@Getter
public class ParseResult {
/**
* 是否解析成功
*/
private boolean success;
/**
* 检测到的 MIME 类型
*/
private String mimeType;
/**
* 提取的文本内容
*/
private String content;
/**
* 提取的元数据
*/
private Map<String, String> metadata;
/**
* 文本长度(字符数)
*/
private int contentLength;
/**
* 错误信息(如果失败)
*/
private String errorMessage;
// 静态工厂方法
public static ParseResult success(String mimeType, String content, Map<String, String> metadata) {
ParseResult result = new ParseResult();
result.setSuccess(true);
result.setMimeType(mimeType);
result.setContent(content);
result.setContentLength(content != null ? content.length() : 0);
result.setMetadata(metadata);
return result;
}
public static ParseResult failure(String errorMessage) {
ParseResult result = new ParseResult();
result.setSuccess(false);
result.setErrorMessage(errorMessage);
return result;
}
}
2.2 创建 Tika 解析服务
@Slf4j
@Service
public class TikaParseService {
/**
* Tika 实例(用于简单操作,如 MIME 检测)
*/
private final Tika tika = new Tika();
/**
* 自动检测解析器
*/
private final Parser parser = new AutoDetectParser();
/**
* 最大文本长度限制(-1 表示无限制,但可能导致内存问题)
* 这里设置为 10MB 字符
*/
private static final int MAX_TEXT_LENGTH = 10 * 1024 * 1024;
/**
* 解析文件,提取文本和元数据
*
* @param file 上传的文件
* @return 解析结果
*/
public ParseResult parseFile(MultipartFile file) {
// 1. 基本校验
if (file == null || file.isEmpty()) {
return ParseResult.failure("文件为空");
}
String originalFilename = file.getOriginalFilename();
log.info("开始解析文件: {}, 大小: {} bytes", originalFilename, file.getSize());
try (InputStream inputStream = file.getInputStream()) {
// 2. 检测 MIME 类型
// 注意:这里需要重新获取流,因为检测会消费流
String mimeType;
try (InputStream detectStream = file.getInputStream()) {
mimeType = tika.detect(detectStream, originalFilename);
}
log.info("检测到 MIME 类型: {}", mimeType);
// 3. 准备解析器组件
// BodyContentHandler: 用于接收解析出的文本内容
// 参数 MAX_TEXT_LENGTH 限制最大文本长度,防止内存溢出
BodyContentHandler handler = new BodyContentHandler(MAX_TEXT_LENGTH);
// Metadata: 用于存储元数据
Metadata metadata = new Metadata();
// 设置文件名,帮助解析器识别
metadata.set(TikaCoreProperties.RESOURCE_NAME_KEY, originalFilename);
// ParseContext: 解析上下文,可以配置额外选项
ParseContext context = new ParseContext();
// 4. 执行解析
try (InputStream parseStream = file.getInputStream()) {
parser.parse(parseStream, handler, metadata, context);
}
// 5. 获取解析结果
String content = handler.toString();
// 6. 清洗文本(去除多余空白)
content = cleanText(content);
// 7. 提取元数据
Map<String, String> metadataMap = extractMetadata(metadata);
// 8. 检查解析质量
if (content.isEmpty()) {
log.warn("文件 {} 解析结果为空,可能是扫描件或加密文档", originalFilename);
return ParseResult.failure("解析结果为空,可能是扫描件或加密文档");
}
log.info("文件 {} 解析成功,提取文本长度: {}", originalFilename, content.length());
return ParseResult.success(mimeType, content, metadataMap);
} catch (IOException e) {
log.error("读取文件失败: {}", originalFilename, e);
return ParseResult.failure("读取文件失败: " + e.getMessage());
} catch (TikaException e) {
log.error("Tika 解析失败: {}", originalFilename, e);
return ParseResult.failure("文档解析失败: " + e.getMessage());
} catch (SAXException e) {
log.error("XML 解析失败: {}", originalFilename, e);
return ParseResult.failure("文档结构解析失败: " + e.getMessage());
} catch (Exception e) {
log.error("未知错误: {}", originalFilename, e);
return ParseResult.failure("解析过程中发生未知错误: " + e.getMessage());
}
}
/**
* 仅检测文件的 MIME 类型
*
* @param file 上传的文件
* @return MIME 类型字符串
*/
public String detectMimeType(MultipartFile file) throws IOException {
try (InputStream inputStream = file.getInputStream()) {
return tika.detect(inputStream, file.getOriginalFilename());
}
}
/**
* 清�洗文本内容
* - 将多个连续空白字符替换为单个空格
* - 将多个连续换行替换为最多两个换行(保留段落)
* - 去除首尾空白
*/
private String cleanText(String text) {
if (text == null) {
return "";
}
return text
// 将 \r\n 统一为 \n
.replaceAll("\\r\\n", "\n")
// 将 \r 统一为 \n
.replaceAll("\\r", "\n")
// 去除每行首尾的空格
.replaceAll("(?m)^[ \\t]+|[ \\t]+$", "")
// 将 3 个及以上连续换行替换为 2 个换行
.replaceAll("\\n{3,}", "\n\n")
// 将多个连续空格/制表符替换为单个空格
.replaceAll("[ \\t]+", " ")
// 去除首尾空白
.trim();
}
/**
* 从 Metadata 对象提取元数据为 Map
*/
private Map<String, String> extractMetadata(Metadata metadata) {
Map<String, String> result = new HashMap<>();
for (String name : metadata.names()) {
String value = metadata.get(name);
if (value != null && !value.isEmpty()) {
result.put(name, value);
}
}
return result;
}
}
2.2.1 核心代码解释
BodyContentHandler:
BodyContentHandler handler = new BodyContentHandler(MAX_TEXT_LENGTH);
这是 Tika 的 SAX 内容处理器,负责接收解析器输出的文本。参数是最大字符数限制,超过会抛出异常。设为 -1 表示无限制(危险,可能 OOM)。
Metadata:
Metadata metadata = new Metadata();
metadata.set(TikaCoreProperties.RESOURCE_NAME_KEY, originalFilename);
Metadata 对象会在解析过程中被填充。提前设置文件名可以帮助解析器做更准确的判断。
AutoDetectParser:
Parser parser = new AutoDetectParser();
parser.parse(inputStream, handler, metadata, context);
AutoDetectParser 会自动根据 MIME 类型选择合适的底层解析器(PDF 用 PDFParser,Word 用 OOXMLParser 等)。
2.3 创建 Controller
@RestController
@RequestMapping("/api/document")
public class DocumentController {
@Autowired
private TikaParseService tikaParseService;
/**
* 解析上传的文档,返回文本和元数据
*
* POST /api/document/parse
* Content-Type: multipart/form-data
*/
@PostMapping(value = "/parse", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResponseEntity<ParseResult> parseDocument(@RequestParam("file") MultipartFile file) {
ParseResult result = tikaParseService.parseFile(file);
if (result.isSuccess()) {
return ResponseEntity.ok(result);
} else {
return ResponseEntity.badRequest().body(result);
}
}
/**
* 仅检测文件的 MIME 类型
*
* POST /api/document/detect
* Content-Type: multipart/form-data
*/
@PostMapping(value = "/detect", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public ResponseEntity<Map<String, String>> detectMimeType(@RequestParam("file") MultipartFile file) {
try {
String mimeType = tikaParseService.detectMimeType(file);
Map<String, String> response = new HashMap<>();
response.put("filename", file.getOriginalFilename());
response.put("mimeType", mimeType);
response.put("size", String.valueOf(file.getSize()));
return ResponseEntity.ok(response);
} catch (IOException e) {
Map<String, String> error = new HashMap<>();
error.put("error", "无法检测文件类型: " + e.getMessage());
return ResponseEntity.badRequest().body(error);
}
}
}
2.4 配置文件上传限制
在 src/main/resources/application.yml 中:
spring:
application:
name: tika-demo
servlet:
multipart:
# 单个文件最大大小
max-file-size: 50MB
# 整个请求最大大小
max-request-size: 50MB
server:
port: 8080
2.5 主启动类
@SpringBootApplication
public class Tika3xApplication {
public static void main(String[] args) {
SpringApplication.run(Tika3xApplication.class, args);
}
}
3. 验证与测试
3.1 使用 curl 测试
测试 MIME 检测:
# 创建一个测试文件
echo "Hello World" > test.txt
# 检测类型
curl -X POST \
-F "file=@test.txt" \
http://localhost:8080/api/document/detect
输出:
{
"filename": "test.txt",
"mimeType": "text/plain",
"size": "12"
}
测试文档解析:
# 解析文本文件
curl -X POST \
-F "file=@test.txt" \
http://localhost:8080/api/document/parse
输出:
{
"success": true,
"mimeType": "text/plain",
"content": "Hello World",
"metadata": {
"X-TIKA:Parsed-By": "org.apache.tika.parser.DefaultParser",
"X-TIKA:Parsed-By-Full-Set": "org.apache.tika.parser.DefaultParser",
"Content-Encoding": "ISO-8859-1",
"resourceName": "test.txt",
"X-TIKA:detectedEncoding": "ISO-8859-1",
"X-TIKA:encodingDetector": "UniversalEncodingDetector",
"Content-Type": "text/plain; charset=ISO-8859-1"
},
"contentLength": 11,
"errorMessage": null
}
测试解析 PDF(如果你有的话):
curl -X POST \
-F "file=@your-document.pdf" \
http://localhost:8080/api/document/parse
3.2 使用 Postman 或 ApiFox 测试
- 打开 API 测试工具,创建新请求
- 方法选择
POST - URL 输入
http://localhost:8080/api/document/parse - 选择
Body→form-data - Key 输入
file,类型选择File - Value 选择你要上传的文件
- 点击
Send
Tika 选择嵌入式还是独立部署运行?
| 维度 | 嵌入 Spring Boot(依赖库) | 单独部署(Tika Server) |
|---|---|---|
| 上手成本 | ✅ 最快:加依赖写代码就能跑 | ⚠️ 多一步:起容器 + 配服务地址 |
| 依赖/体积 | ⚠️ 依赖树大,fat jar 变大;可能遇到依赖冲突 | ✅ 依赖都在容器里,应用更“干净” |
| OCR/系统依赖 | ⚠️ OCR、字体、图像库等可能需要装系统包,环境差异多 | ✅ 镜像通常把 OCR 等打包好了,环境一致 |
| 资源隔离(CPU/内存) | ⚠️ 解析大文件很吃内存/CPU,可能拖慢甚至打挂你的业务进程 | ✅ 解析吃资源在容器里;Tika 挂了业务不一定跟着挂(可重启/限额) |
| 安全隔离(不可信文件) | ⚠️ 风险直接进你的业务 JVM | ✅ 解析“危险面”隔离到独立服务更合理;但仍要做版本升级/限制策略 |
| 扩展性 | ⚠️ 每个业务实例都要带一份解析能力,横向扩展成本高 | ✅ 多个业务共享一组 Tika;可以单独水平扩容 |
| 性能 | ✅ 少一次网络传输,延迟更低 | ⚠️ 多一次 HTTP 传输(但局域网一般可接受);吞吐可靠扩容补 |
| 多语言/多项目复用 | ⚠️ 主要服务于 Java 项目 | ✅ 任意语言都能 HTTP 调,复用性强 |
| 运维复杂度 | ✅ 少一个组件 | ⚠️ 多一个组件(监控、日志、限流、鉴权等) |
更适合嵌入式的场景:
- 课程/作业/小项目:就一个 Spring Boot 服务,上传一些 doc/pdf,规模不大
- 部署环境简单:不想多维护一个容器服务
- 解析量不高:偶尔解析、文件不大、并发低
更适合 Tika Server 独立部署的场景:
- 你在做 知识库入库/RAG 数据准备:大量文件、批处理、并发高
- 文件来源更“野”:各种 PDF(含扫描件)、各种 Office、各种编码
- 你希望解析失败/卡死不影响主业务:把解析从业务进程剥离
- 你有多种语言/多个服务要复用同一套解析能力
文末总结
1. 讲了什么
-
为什么文档解析不是一个
readFile()能搞定的事- 文件格式多样、后缀会骗人、编码混乱、扫描件无法直接读文字
-
Apache Tika 解决什么问题
- 自动检测文件类型
- 统一提取文本和元数据
- 支持 1000+ 种格式
-
核心概念
- MIME 类型:文件的真实身份
- 文本抽取:拿到可用的文字
- 元数据抽取:拿到文档属性
- OCR:让图片“开口”说话
-
两种集成方式
- 作为 Java 库:简单但依赖重
- 调用 Tika Server:隔离且可扩展
-
工程实践
- 解析质量检查
- 超时与内存控制
- 异常处理与日志
2. 在 RAG 系统中的位置
原始文档 → [Tika 解析] → 干净文本 + 元数据 → 文本切片 → 向量化 → 向量数据库
↑
你学会了这一步
Tika 是 RAG 数据管道的第一道关卡,解析质量直接影响后续所有环节。
3. 下一步学什么
| 方向 | 内容 |
|---|---|
| 文本切片 | 如何把长文本切成适合检索的片段 |
| 向量化 | 使用 Embedding 模型将文本转为向量 |
| 向量数据库 | Milvus / Pinecone / Chroma 等 |
| 检索策略 | 相似度搜索、混合检索、重排序 |
| Prompt 工程 | 如何组装检索结果和用户问题 |