为什么要本地部署大模型?
从一张病历说起
前面几篇 RAG 的文章里,咱们的代码一直是一个套路:OkHttp 构造 HTTPS 请求,打到 SiliconFlow 的 /v1/chat/completions,拿回模型的回答。调用链短、上手快,写 Demo 很舒服。
直到某天你接了个新项目。
你在一家做医疗信息化的公司,客户是某三甲医院。需求是给医生做电子病历辅助录入和智能问诊助手,背后挂着医院十几年积累的病例库、临床路径、用药指南,外加实时查询 HIS 系统里的患�者历史。你拿之前写好的 RAG 代码去做 PoC,效果不错,客户挺满意,顺利推到了方案评审。医院信息科的科长看了一眼架构图,问了一句:
你这个大模型接口,是打到阿里云还是腾讯云?病历数据出院内网了吗?
你愣了一下。
赶紧解释:只传了相关的检索片段,患者姓名、身份证号都做了替换。科长摆摆手:回去看一下等保三级的要求和《个人信息保护法》,患者的就诊记录、诊断结论、用药方案,就算脱敏过,只要涉及身份可识别的个人健康信息,都不能在这种场景下出院内网。
云端 API 再方便,也有撞墙的时候。墙那头是数据主权、合规红线、成本账单、离线环境——撞上任何一条,你都得面对同一个问题:把大模型挪到自己的机器上跑。
这就是本地部署。
这一篇不讲怎么装 Ollama,也不讲 vLLM 怎么调参,那些留给后面几篇。这一篇只想把三件事讲明白:
- 已经有了 Qwen、DeepSeek、OpenAI 这些云端 API,为什么有人还要自己本地部署?
- 本地部署的模型,到底从哪里来?
- 本地部署有哪些中间件,它们之间什么关系?
搞清楚这三件事,你再去装 Ollama、配 vLLM,心里才有数。
云端 API 这么方便,为什么还要自己部署
1. 先别急着本地化,云端 API 做对了什么
在说云端 API 的短板之前,我想先客观地把它的好处摆出来。因为我见过太多项目,一上来就喊着要自主可控,花几十万堆一堆 GPU,最后跑出来的效果还不如直接调 API。对大多数个人项目、初创团队、中小规模的 RAG 系统来说,云端 API 就是最优解,没有之一。
它好在哪里:
-
开箱即用:注册账号、充值、拿 API Key,十分钟就能跑通第一个 Chat 请求。你之前跟着系列文章走下来应该深有体会。
-
永远跑在最新最强的模型上:上周 DeepSeek 发了新版本,云厂商今天就上架了;你本地跑的 Qwen3 还没升完,别人已经在用 Qwen3.5 了。模型迭代速度这几年快到离谱,云 API 这一层永远是业界最前沿的工具箱。
-
按量付费,闲时零成本:项目没上线、流量没起来、还在 Demo 阶段,一个月花几十块、几百块就能把架子搭起来。本地部署一上来就是几万块一台的显卡,再加电费和运维,起步成本天差地别。
-
免运维:模型升级、硬件扩容、节点故障、负载均衡,都是云厂商的事。你只需要关心自己的业务代码。
-
弹性扩容:双 11 峰值过来了,云 API 后端自己扩;你本地部署面对突发流量,只能眼睁睁看着队列堆积。
这些优势摆在这里,意味着一件事:如果你的项目不满足后面要讲的那五类场景里的任何一类,就老老实实用云端 API,别折腾本地部署。本地部署不是炫技,更不要跟风,它是被业务诉求逼出来的��选择。
如果本地跑模型,光硬件就是一笔大投入——一台能插多卡 GPU 的服务器,起步价就不便宜,而且后续想扩容,要么加卡要么加机器,预算是持续往上走的。硬件到位了,还有个容易忽略的问题:公司机房的供电和散热能不能扛住?如果园区断电没有 UPS 兜底,服务直接就挂了。要保障稳定运行,往往得把机器托管到 IDC 机房,光机柜租赁加带宽,一年就是好几万。
硬件成本 + 托管成本 + 日常运维(驱动升级、故障排查、散热维护),这些加起来,对绝大部分中小公司来说,本地跑模型的性价比其实很低。除非你有明确的数据合规要求或者超大规模的调用量能把硬件成本摊薄,否则直接用云端 API 几乎总是更务实的选择。
算一笔具体的账:生产和测试环境起码各一台 GPU 服务器,哪怕配置相同,华三的机器一台就要 10~13 万。拿 Qwen3.5-32B 举例,单机至少两张英伟达 L20 才能跑起来,一张卡大概 2.6~2.8 万,两套环境 4 张卡,小 10 万。服务器加显卡,里外里 30 万就没了——公司能不能靠这套东西挣回钱还不好说呢,硬件采购单得先签了。
而且 32B 的模型也就够跑跑内部服务。但凡业务上点强度——面向客户的对话、复杂的多步推理——起码得上 70B 甚至更大的模型,显卡数量翻倍、服务器规格升档,费用更是成倍往上走。
2. 但有五类场景,云端 API 就不合适了
2.1 数据合规与隐私:有些数据一个字节都不能出门
开篇那个病历的故事不是编的,几乎每一家做医疗信息化、金融科技、政务系统的公司都遇到过。这里的核心不是我怕云厂商不靠谱——人家的数据安全做得可能比你自建的机房还好——而是监管法规和客户合同里写死的硬约束。
做医疗的,《医疗机构信息系统安全等级保护基本要求》管着你,三级系统的患者信息不能随意出院内网。做金融的,银保监和人行的监管办法管着你,核心业务数据要留痕在行内。做政务的,等保三级以上加上信创要求,数据离境基本没可能。做企业内部工具的,你公司自己的代码、财报、客户名单,让它飘到一个你不掌控的外部 API 上,一旦出事问责都问不明白。做 To B 业务的,客户合同里很可能明确写着乙方不得将甲方数据传输至任何第三方服务,你直接违约。
所以只要你做的是合规敏感行业,本地部署不是选项,是必选项。
2.2 成本结构:量大了之后云 API 不一定划算
云 API 便宜,是建立在你用得少的前提上的。一旦业务量真的起起来,账单会让你重新算。
云 API 的计费方式你已��经很熟悉了:按 token 收费,按量线性增长。调用量翻倍,成本就翻倍,中间没有任何规模效应。这对低频和不确定流量的业务是巨大的优势,但反过来,对高频稳定调用就是个问题——你每天都在付重复的钱。
自建的成本结构完全相反,大头是固定成本:服务器硬件(或 GPU 租用)、电费机房、中间件运维、人力投入。这些不管你一天打十次还是打一百万次,都得花。但一旦固定成本摊下去了,每次调用的边际成本几乎可以忽略。
两种成本曲线一摆,拐点就出来了:
- 调用量低的时候,云 API 的按量成本远远低于自建的固定成本,云 API 更划算
- 调用量上来之后,云 API 的账单线性爬升,自建的固定成本被摊薄,自建开始有成本优势
- 中间有一段灰色区间,谁划算取决于你的调用分布(持续稳定 vs 波峰波谷)、选用的模型档位、硬件方案(自购 vs 租用)
具体的拐点在哪?没有一个放之四海而皆准的数字,影响因素太多:
- 你用的是哪档模型(7B、32B、70B、70B+ 每档价格差好几倍)
- 输入输出 token 的比例(RAG 或者 Agent 场景输入长输出短,和闲聊类完全不同)
- 流量的波峰波谷幅度(峰谷差 10 倍的业务成本很不可控,因为不用的时候机器完全闲置)
- 自建方案(自购整机 vs 云上租 GPU vs 包年包月 vs 按量)
- 是否复用已有运维人力
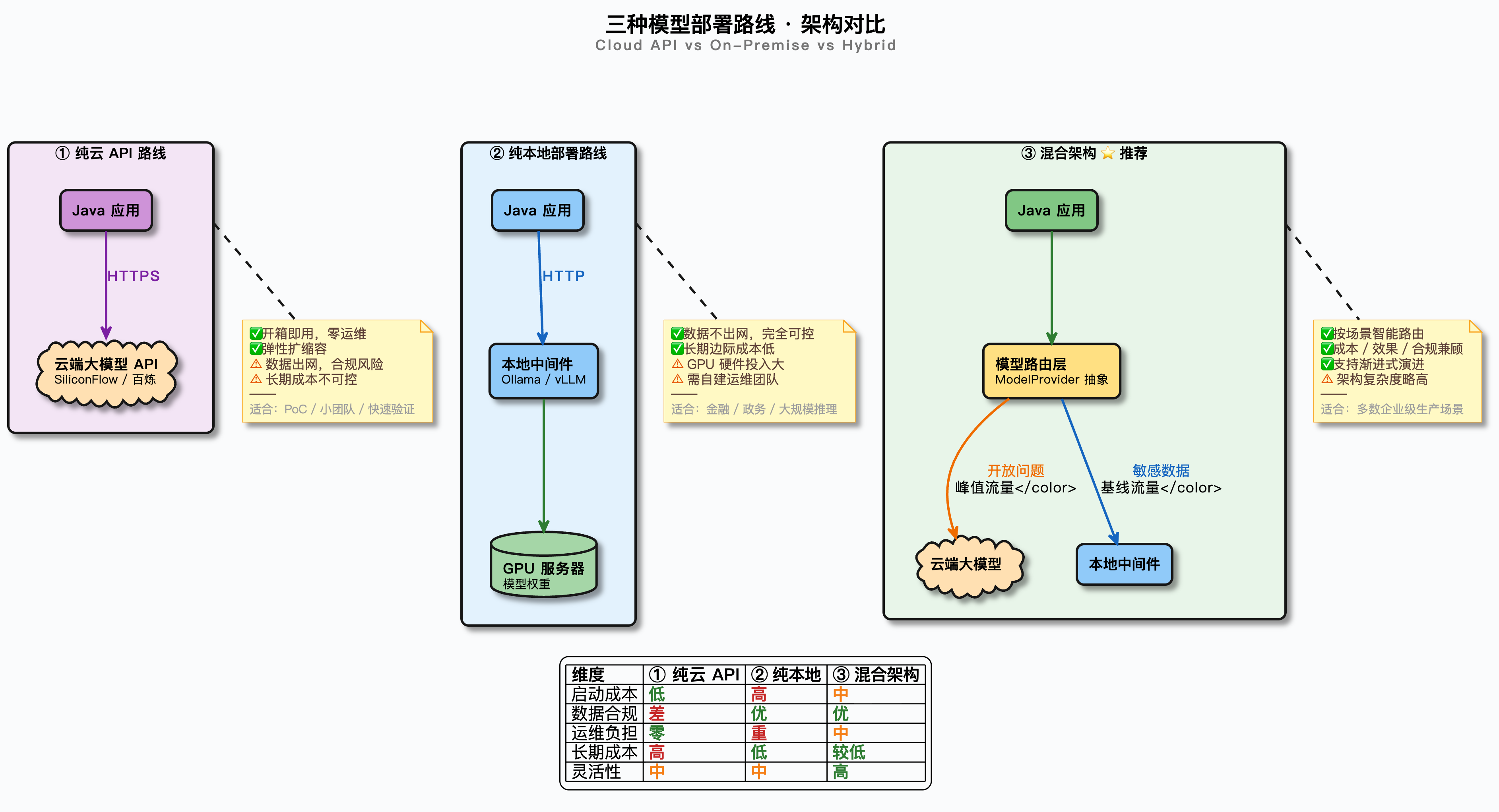
一个可参考的方向性结论:日均调用规模很小的时候几乎一定用云 API 更便宜,规模起来之后要开始认真算账。中间地带最稳的做法是混合架构——基线流量本地消化、峰值溢出到云端,既压住成本又留了弹��性。
还有一笔容易被忽略的隐性成本:自建意味着你团队里要有懂推理引擎、懂 GPU 运维的人,或者你自己得投入精力去学。这部分人力成本在前期 ROI 测算时最容易被漏掉,后面的误区章节会再讲。
所以这一节的结论不是量大就要自建,而是量大了之后,你得有意识去算这笔账,而不是默认跟着云 API 的账单线性增长下去。
2.3 稳定性与可控性:不想被卡脖子
云 API 带来的另一个看不见的风险,是你的关键业务被绑在了别人的 SLA 上。几个真实会被坑的点:
-
限流:云厂商给你的 QPS 是有上限的,触发限流的时候你的业务就会报 429。临时客户申请提额,客服周转半天,晚上十点高峰期你已经被用户骂爆。
-
模型下线:某个 API 厂商宣布下架某款老模型,给你两个月迁移期。你项目里已经为这个模型专门调优过 prompt 的所有效果,全部要重跑一遍回归。
-
价格调整:24、25 年国内大模型打价格战,价格腰斩再腰斩,对用户是好事。但反过来呢?某天供应商说我们要涨价了,你的月度账单直接翻倍,你下不下得了线?
-
区域可用性:你做出海业务,主力用户在东南亚和中东,你用的国内云厂商 API 在境外访问速度飘忽不定,甚至被防火墙拦截。跨区域延迟就能毁掉用户体验。
-
上游故障:某家主流大模型 API 某个月突然挂了两小�时,全国一半创业公司 AI 产品瘫痪,社交媒体上一片骂声。你的 on-call 工程师除了干等上游恢复之外,什么都做不了。
本地部署解决不了所有问题,但它把这些不可控风险变成了可控风险。服务器挂了你能修,模型慢了你能调,价格谁也说了不算,区域可用性你自己决定。对关键业务链路来说,这种可控性本身就有价值。
2.4 离线与边缘场景:网络本身就是奢侈品
有些场景根本没有云这个选项。
-
产线设备:工厂车间的 OT 网络(操作技术网络)通常和外网物理隔离,或者通过单向光闸只允许数据出、不允许数据入。AI 质检、设备预测性维护这些场景要用大模型,只能本地部署。
-
车载系统:车在高速上跑,过隧道、到山区,4G/5G 信号时断时续。语音助手、智能座舱不能等着网络恢复才回应用户。现在车企普遍在做云端大模型 + 车端小模型的架构,车端那部分必须本地化。
-
军工与涉密:不展开,懂的都懂。
-
海外园区/信创机房:有些海外工厂受当地网络管制,有些国产化机房彻底切断外网,只能用内网部署的模型。
-
隔离开发环境:金融核心业务系统的开发测试环境,通常也是隔离的。
这些场景下,本地部署不是要不要的问题,是只能本地的问题。
2.5 深度定制与微调:拥有模型底座才能改它
云 API 给你的是调用权,不是所有权。有些事情,你只有真正拿到模型权重才能做:
-
垂直领域微调:医疗领域的术语、法律条款的专业表达、金融行业的业务黑话,通用大模型不一定吃得透。用你的私有数据做增量训练(全参微调或 LoRA),让模型真正懂你的行业。这个操作必须有模型权重才能做——你得能打开模型的参数,用自己的数据去调整它,而不只是在外面喂 prompt。
-
训练专用的小模型:假设你有一个很具体的业务场景,比如合同条款分类、工单意图识别,通用大模型杀鸡用牛刀,你想训练一个又小又快的专用模型。不管是从零训练还是从大模型蒸馏(让大模型当老师,教一个小模型学会同样的判断能力),你都需要掌握模型权重。
-
推理行为的精细控制:本地部署后你可以直接控制推理引擎的行为。比如强制模型输出严格的 JSON 格式(不是靠 prompt 提示,而是在解码阶段直接约束哪些 token 能被生成)、调整采样策略的每一个细节、在推理过程中做自定义的后处理。这些在 API 调用层面要么做不了,要么只能有限地做。
-
极致性能优化:针对你的硬件和业务特点做专门的优化——选择最合适的量化方案、调整批处理策略、针对高频重复请求做缓存复用。云 API 做的是通用优化,照顾的是所有用户的平均水平,不会为��你的业务单独调。
如果你的业务需要这些,API 调用再方便也满足不了,只能本地部署。
3. 决策表:我的项目到底该走哪条路
把五类诉求摆在一起,形成一张快速自查表:
| 项目类型 | 数据合规 | 成本敏感度 | 稳定可控需求 | 离线要求 | 定制微调 | 推荐路线 |
|---|---|---|---|---|---|---|
| 个人 Demo / 学习项目 | 低 | 低 | 低 | 无 | 无 | 纯云 API |
| 初创 SaaS / 中小 RAG 系统 | 低-中 | 低-中 | 中 | 无 | 低 | 纯云 API(先跑起来) |
| 企业内部知识库(普通数据) | 中 | 中 | 中 | 无 | 低 | 云 API,因为调用量不高 |
| 医疗 / 金融 / 政务 | 高 | 中 | 高 | 中 | 中 | 纯本地(合规硬约束) |
| 高频 C 端 AI 产品 | 中 | 高 | 高 | 无 | 中 | 混合架构(峰值云端、基线本地) |
| 边缘 / 离线 / 车载 / 产线 | - | - | - | 高 | - | 纯本地(别无选择) |
| 需要深度行业微调 | 中-高 | 中 | 中 | - | 高 | 纯本地(拥有权重) |
单独说一下混合架构,这是大多数有一定规模的企业的现实选择:
- 敏感数据、核心业务走本地模型,保证数据不出内网
- 开放性问题、创意类任务走云端顶级模型,拿效果
- 基线流量本地消化控成本,峰值流量溢出到云端保可用性
- 不同模型按能力路由:简单问题本地小模型秒回,复杂问题云端大模型深思
Ragent 项目里的模型路由层,就是为混合架构而设计的——这个我们后面会讲到。