21小节:Prometheus配置oneThread运行时监控数据采集
作者:程序员马丁
Ragent AI —— 从 0 到 1 纯手工打造企业级 Agentic RAG,拒绝 Demo 玩具!AI 时代,助你拿个offer。
Prometheus 配置 oneThread 运行时监控数据采集,元数据信息:
- 什么是线程池oneThread:https://t.zsxq.com/5GfrN
- 代码仓库:https://gitcode.net/nageoffer/onethread —— 申请项目权限参考上述线程池项目链接
- 章节难度:★★☆☆☆ - 中等
- 视频地址:本章节内容简单,无
©版权所有 - 拿个offer-开源&项目实战星球专属学习项目,依据《中华人民共和国著作权法实施条例》和《知识星球产权保护》,严禁未经本项目原作者明确书面授权擅自分享至 GitHub、Gitee 等任何开放平台。违者将面临法律追究。
内容摘要:本文深入介绍 oneThread 动态线程池框架与 Prometheus 监控系统的集成实践,重点阐述Prometheus 架构原理、Docker 部署配置和指标采集任务的完整实现。
课程目录如下所示:
- 前言
- Prometheus 介绍
- Docker 安装 Prometheus
- Prometheus 控制台操作指南
- PromQL 查询语言实践
- 文末总结
前言
在上一篇文章中,我们详细介绍了 oneThread 框架的 Micrometer 指标监控实现。通过 Micrometer 的抽象层,我们的应用已经能够以标准格式暴露线程池监控指标。但是,要真正发挥这些指标的价值,我们还需要一个专业的监控系统来采集、存储和分析这些数据。
想象一下这样的场景:
周一早上 9 点,你刚到公司就收到了运维同事的紧急消息:"订单服务的线程池好像有问题,处理速度明显变慢了。" 在传统的监控方式下,你可能需要登录服务器查看日志,或者临时写脚本来获取线程池状态。但有了 Prometheus 监控系统,你只需要打开浏览器,访问 Prometheus 控制台,输入一个简单的查询语句:
dynamic_thread_pool_active_size{application_name="order-service"},立即就能看到所有线程池的活跃线程数变化趋势。
这就是 Prometheus 的好用之处——它不仅能自动采集应用的监控指标,还能提供强大的查询能力和历史数据分析功能。
相比传统的监控方案,Prometheus 具有以下显著优势:
- Pull 模式采集:主动从应用拉取指标,避免了推送模式的网络复杂性。
- 时间序列存储:专门为监控数据设计的存储引擎,查询性能优异。
- PromQL 查询语言:功能强大的查询语言,支持复杂的数据分析和聚合。
- 服务发现机制:自动发现和监控新的服务实例。
- 告警规则引擎:内置告警功能,支持多种通知方式。
Prometheus 介绍
1. 什么是 Prometheus?
Prometheus 是一个开源的系统监控和告警工具包,最初由 SoundCloud 构建。自 2012 年诞生以来,许多公司和组织都采用了 Prometheus,并且该项目拥有非常活跃的开发者和用户 社区。它现在是一个独立的开源项目,由任何公司独立维护。为了强调这一点并明确项目的治��理结构,Prometheus 于 2016 年加入了 云原生计算基金会,成为继 Kubernetes 之后第二个托管项目。
Prometheus 将其指标作为时间序列数据收集和存储,即指标信息与记录时的时间戳以及可选的键值对(称为标签)一起存储。
2. 特性
Prometheus 的主要特性包括:
- 一个多维数据模型,其中时间序列数据由指标名称和键/值对标识。
- PromQL,一种灵活的查询语言,用于利用这种多维性。
- 不依赖分布式存储;单个服务器节点是自主的。
- 时间序列收集通过 HTTP 上的拉取模型进行。
- 通过中间网关支持推送时间序列。
- 通过服务发现或静态配置发现目标。
- 支持多种图形和仪表盘模式。
3. 什么是指标(Metric)?
指标在通俗意义上是数值测量。术语“时间序列”是指随时间记录的变化。用户希望测量的内容因应用程序而异。对于 Web 服务器,可能是请求时间;对于数据库,可能是活动连接数或�活动查询数等等。
指标在理解应用程序为何以某种方式工作方面发挥着重要作用。假设您正在运行一个 Web 应用程序并发现它运行缓慢。要了解应用程序发生了什么,您需要一些信息。例如,当请求数量很高时,应用程序可能会变慢。如果您拥有请求计数指标,则可以确定原因并增加服务器数量以处理负载。
4. 组件
Prometheus 生态系统由多个组件组成,其中许多是可选的
- 主 Prometheus 服务器,它抓取并存储时间序列数据。
- 用于对应用程序代码进行埋点的客户端库。
- 一个用于支持短生命周期作业的推送网关。
- 用于 HAProxy、StatsD、Graphite 等服务的专用导出器。
- 一个用于处理告警的告警管理器。
- 各种支持工具。
大多数 Prometheus 组件都是用 Go 编写的,这使得它们易于构建并部署为静态二进制文件。
5. 架构
此图展示了 Prometheus 及其部分生态系统组件的架构:
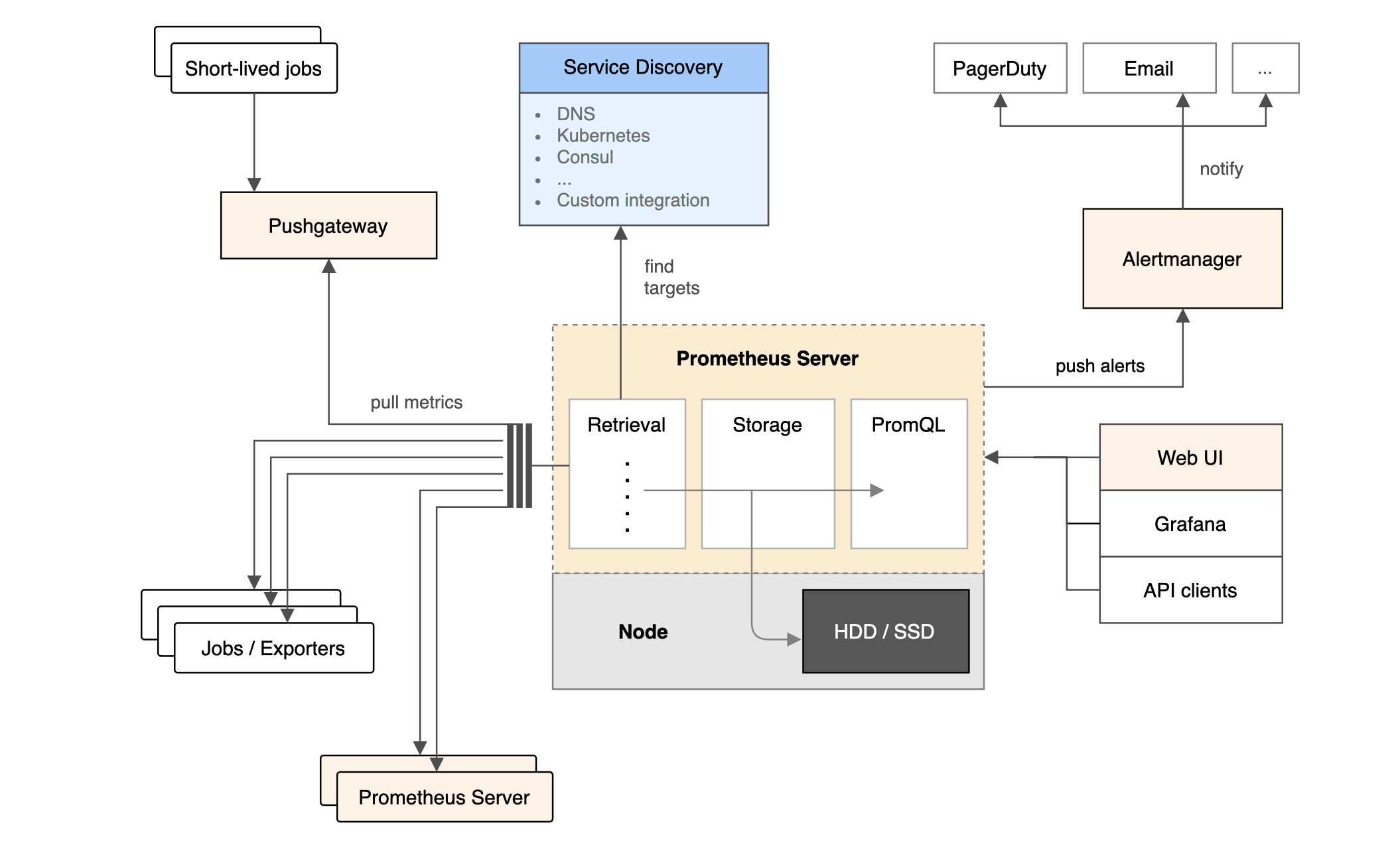
Prometheus 从已埋点的作业中抓取指标,可以直接抓取,也可以通过中间推送网关抓取短生命周期作业的指标。它将所有抓取的样本存储在本地,并根据这些数据运行规则,以聚合并记录现有数据中的新时间序列或生成告警。Grafana 或其他 API 消费者可用于可视化收集到的数据。
6. 为什么选择拉而不是推?
Prometheus 默认采用的是一种 “拉模型(Pull Model)” 架构,它会主动周期性地拉取被监控目标的指标数据。每个被监控的服务需要暴露一个支持 Prometheus 格式 的 HTTP 接口,通常路径是 /metrics(如 Spring Boot 的 /actuator/prometheus)。
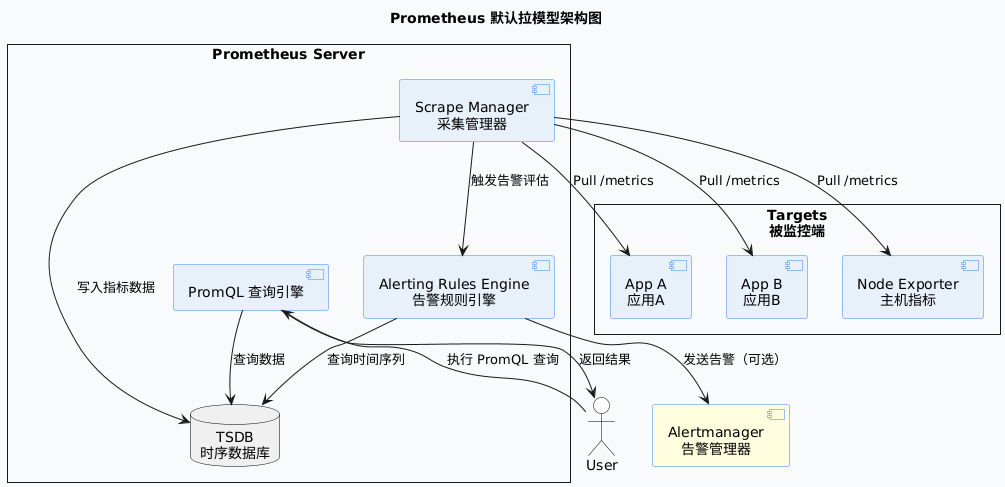
通过 HTTP 进行拉取有很多优点:
- 根据需要启动监控实例,例如在本地开发时在笔记本电脑上启动一个 Prometheus 实例进行调试。
- 更容易、更可靠地判断某个目标是否宕机。
- 可以手动访问目标服务的指标接口,直接通过浏览器检查其健康状态。
总体而言,Prometheus 认为拉模式略优于推模式,在考虑监控系统时,拉和推不应该成为主要考虑点。
对于必须推送的情况,Prometheus 同时也提供了 Pushgateway 组件。
Docker 安装 Prometheus
1. 简易版安装
考虑到部分同学对 Docker 这些命令不太熟悉,常规安装 Prometheus 需要挂载配置文件地址,同时 Windows 和 Mac、Linux 路径方式还不太一样,这里马哥希望在 Docker 启动命令中直接传入 Prometheus 配置内容,不挂载本地配置文件,实现“一条命令部署 Prometheus 并用自定义配置”。
虽然 Prometheus 官方镜像不支持直接通过命令行参数传入完整配置,但是玩了个花活实现需求。使用 echo + docker run + --entrypoint 动态生成配置: